By Will Braynen
There is map-reduce and then there is MapReduce. Functional languages Lisp and Haskell, as well as non-functional languages such as Swift and Python, have functions called map and reduce (or fold); this is what I mean by “map-reduce”. “MapReduce”, on the other hand, is a design pattern in distributed computing that’s inspired by map-reduce, or so is the typical framing. The connection, however, is more than merely inspirational or, rather, the inspiration, I think, could also run in reverse: an iPhone, for example, has more than one core and so, in theory, we could parallelize the work and then re-combine the results even when there is no computer cluster (assuming of course that the cost of cores communicating with each other would not be too high). But first, let me explain what map-reduce and MapReduce both are.
MapReduce is a design pattern for efficiently crunching large datasets by parallelizing the work using a bunch of computers strung together in a cluster and then combining the results of the parallelized work. Jeffrey Dean and Sanjay Ghemawat described this use case and the original MapReduce ‘programming model’ in their 2004 Google whitepaper. (Apache Hadoop is an open-source implementation of this pattern.)
The idea behind MapReduce is simple: divide parallelizable work (the “map” step) and then recombine the results from the cluster’s individual nodes (the “reduce” step). The idea was influential in part because it could be implemented with commodity hardware, thus using commodity hardware to process terabyte-sized datasets.
![[5,7,4,12,1].map{ $0 * 2 }.reduce(0, +)](https://images.squarespace-cdn.com/content/v1/591e792015d5dbeb5801abf3/1548313892023-Y4IYRRMZ2G905AQL6JBY/Screen+Shot+2019-01-23+at+11.11.14+PM.png)
[5,7,4,12,1].map{ $0 * 2 }.reduce(0, +)
Note that the diagram I drew above makes the reduce step look like it is not parallelizable. The map step is parallelizable, but reduce is not. That’s because (a) this is the simplest example to show and (b) in functional programming the reduce step is (typically? always?) a single-thread non-parallelizable task. In distributed computing, on the other hand, the reduce step can also be parallelizable and probably often is; for example, see my answer at this stackoverflow, which is a quiz question I saw in Indranil Gupta’s Coursera course on distributed computing. But for the sake of this article, let’s assume that the reduce step is not parallizable, which is a safe assumption if you are writing Swift code rather than setting up server clusters for distributed computing.
Some applications of MapReduce in distributed computing. The PageRank algorithm typically gets the credits for Google’s search engine, but MapReduce was an important practical component of making it work prior to 2010. The PageRank algorithm needs to know which web pages link to a particular page. So, once your web crawler constructs a graph in which nodes represents the web pages and node A is connected to node B if, and only if, web page A links to web page B, you would then have to reverse this graph to give the PageRank algorithm what it needs. You would need to compute the transpose of this graph by reversing all the edges, which is work you can parallelize by using MapReduce. Similarly, perhaps a simpler application of MapReduce is a distributed grep.
Cool idea. Distributed computing aside, you can try out Swift’s map and reduce functions in Xcode’s Playground. I don’t think Apple’s compiler does this today, but if the compiler were smart enough, it could in theory take advantage of multiple cores to parallelize the map step. In other words, potentially, this is not merely about syntactic sugar and so is not merely about expressing computational ideas concisely or declaratively. In theory, it could lead to the parallelization of the map step, even on an iPhone.
But back to earth. I rarely come across the need for map-reduce in my daily job, but the other day I did and I was glad I knew it because it helped me solve a more complicated problem in five minutes with a perfectly readable one liner. So, below I will give a few examples of this pattern, so that you’d know it too. And if you already know it, then maybe this would be a handy refresher or reference should you come across a need for it but find yourself forgetting the particulars. While I will use Swift to illustrate map-reduce, map-reduce is a general programming technique and so is not specific to Swift.
The map step
Let’s say you have a list of numbers expressed as an array of integers:
[5, 5]
This array is your input. What you want instead, as output, is an array just like this one, but with each element doubled. In other words, you want this output:
[5*2, 5*2]
The function map takes a closure as an argument, so the above is really shorthand for the following, which is also valid Swift syntax:
[5, 5].map({ $0 * 2 })
where $0 refers to the first argument passed to the closure.
If you were writing in ANSI C equipped with nothing but Kernighan and Ritchie’s C Bible, a for-loop might be appropriate. But we have higher-level tools available to you, so we should use them. In Swift, the expression that does this for you is:
If you don't like the `$0` syntax, you could also write:
[5, 5].map { a in a * 2 }
[5, 5].map { $0 * 2 }
Note that this work is parallelizable. That’s because you do not need the result of the first calculation (the first element of the array multiplied by 2) to perform the second calculation (the second element of the array multiplied by 2), nor do you need the result of the second calculation to perform the first calculation. You can perform both calculations independently of each other. You can perform both in parallel.
If you want to dig a little deeper and a little sideways: using the same reasoning, vectorization (by which I really mean array programming) is also friendly to optimization via parallelization. For example, in the context of machine learning, here is a LaTeX note (in PDF) I coughed up for a friend some years ago the computation in which is typically parallelized by modern linear-algebra libraries.
The reduce step
The zero (the first argument to the `reduce` function just below) is the initial value that `reduce` should use when calculating the result.
Let’s assume that, given some array as input (e.g. [10,10] from above), you want to add up all the elements in the array. In Swift, you could do it like so without any for-loops:
[10,10].reduce(0, +) // 0 + 10 + 10 = 20
If we wanted to multiply the array’s elements by each other, then we would instead start with 1 like so:
[10,10].reduce(1, *) // 1 * 10 * 10 = 100
Combining the two steps
You can use map by itself and reduce by itself. But, honoring Dean’s and Ghemawat’s original paper and both the MapReduce programming model and the map-reduce pattern, you could combine the two.
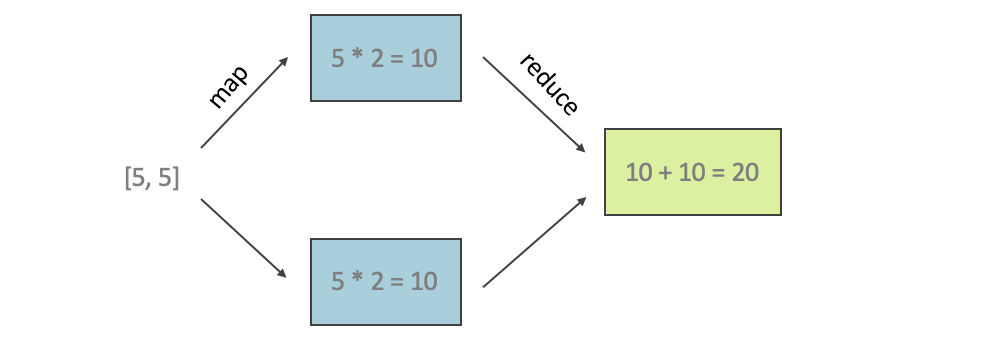
In Swift, combining what we did above might look like this:
[5, 5].map { $0 * 2 }.reduce(0, +)
This means that we take the array [5,5], multiply each array element by 2 (the map step) and then add up all the array elements (the reduce step). In other words, the input is [5,5] and the output is 0+5*2+5*2=20.
A Cluster ~ Multiple Cores
In a sense, there is a tiny compute cluster inside every iPhone. If a mobile device has more than core, then work can be parallelized. This is the map step. If we can subsequently recombine our computations—combine (“reduce” or “fold”) the results of the parallized work—then we would in fact be performing MapReduce inside one smart phone.